一直以来的一个想法,现在有新的思路的就写出来看看。
自动化Web漏洞扫描器是渗透测试亘古不变的话题。把当前一直重复的手工劳动和新的思路转化为自动化工具,利用技术和程序实现为自己节省时间是一件非常有趣的事情。然而,自动化的路坑却不少。其中误报就是一件比较蛋疼的事情,XSS的误报尤其蛋疼。当前众多扫描器的XSS插件都存在误报的情况,我们来看一下大部分扫描器的XSS检测思路,我写了一个简单的Python函数来描述它,当然实际的通用XSS检测插件肯定会比这个要复杂的多,我只截取了一部分来说明思路:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import requestsheaders={} def xss_detect (method='GET' , querylist=[], url='' ) : params = {} resp = None payload = '-->\'"><script>alert(1);</script>' if method == 'GET' : for query in querylist: params[query] = payload resp = requests.get(url, params=params, headers=headers) if resp: if '<script>alert(1);</script>' in resp.content: return True else : return False
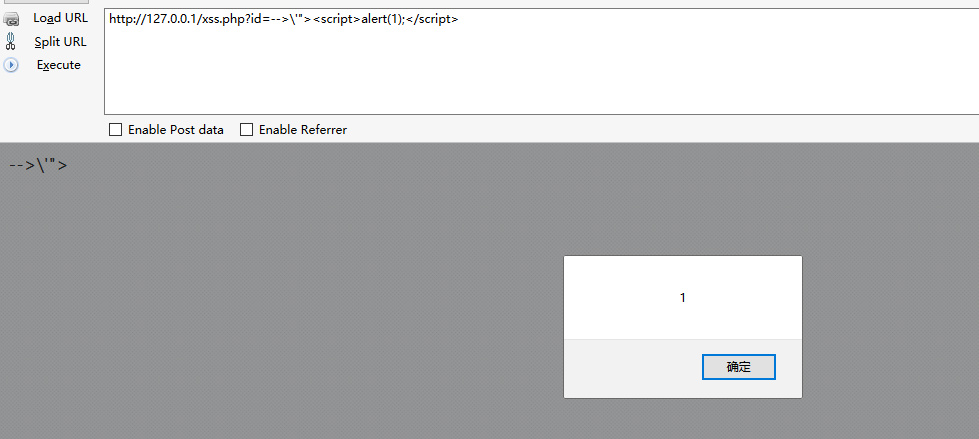
再准备一个有XSS漏洞的php脚本:
1 2 3 4 <?php $id = $_GET['id' ]; echo $id;?>
测试:
由脚本可知,当前的XSS自动化测试思路一般都是给GET或POST参数传入Payload,并正则匹配检测返回的响应中是否含有我们构造payload的完整的html标签(不一定是<script>标签,见过用<H1>的=.=),如果有则判断该页面含有XSS漏洞。
这里的误区在于html页面含有闭合的<script>含有payload的标签,是否就代表JS可执行呢?
我们来看下面这种情况:
1 2 3 4 5 6 7 8 9 10 11 12 <?php $id = $_GET['id' ]; $black_list = array ('"' , "'" ); foreach ($black_list as $key => $value) { $id = str_replace($value, '' , $id); } echo '<input type="text" name="" value="' .$id. '">' ;?>
该php脚本过滤掉了双引号和单引号,并把GET请求中获得的参数添加的input的value属性中,这种情况依照原本xss检测的方法,会出现误报,即虽然从http返回中能检测到闭合完整的<script>标签,但实际该js是不执行的。
其余会产生类似误报的情况也很多,这是一直困扰我的一个问题。直至我在前天重新温习爬虫知识的时候,把爬虫的某项知识和这个联系在了一起,有了一个新的思路。
在SQL注入的自动化检测里面,我们会力求出数据或输出由SQL语句生成的字符串,我们的正则是去匹配sql生成字符串而非sql语句,这样能保证sql语句正确执行了。例如我们payload是select md5(0x2333333),正则匹配查找5e2e9b556d77c86ab48075a94740b6f7,这样就能大幅度减小误报率。那XSS是否也能用这样的思路呢?可惜的是,几乎所有的http请求库都不会返回js执行之后的结果而只会返回未执行的js代码:
1 2 3 4 In [1 ]: import requests In [3 ]: r = requests.get('https://127.0.0.1:8080/html.html' ) In [4 ]: r.content Out[4 ]: '<!DOCTYPE html>\n<html>\n<head>\n <title>111</title>\n</head>\n<body>\n<script type="text/javascript">\n document.body.appendChild(document.createTextNode(String.fromCharCode(84,48,48,76,83)));\n</script>\n</body>\n</html>'
很明显requests库不会像浏览器一样去执行JavaScript。既然requests库不行,那么是不是有其它Python库可以实现模拟浏览器执行js,返回被js操作过的dom树的情况呢?python-qt4有可以模拟浏览器操作的Web工具库,只要是浏览器支持的操作它一般都能模拟。使用PyQt4.QtWebKit就可以执行js,返回js执行之后的结果。我们写一个小demo来验证一下该想法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import sys from PyQt4.QtGui import * from PyQt4.QtCore import * from PyQt4.QtWebKit import * from lxml import html class Render (QWebPage) : def __init__ (self, url) : self.app = QApplication(sys.argv) QWebPage.__init__(self) self.loadFinished.connect(self._loadFinished) self.mainFrame().load(QUrl(url)) self.app.exec_() def _loadFinished (self, result) : self.frame = self.mainFrame() self.app.quit()
1 2 3 4 5 In [3 ]: url = 'https://192.168.1.126:8080/html.html' In [4 ]: r = Render(url) In [5 ]: result = r.frame.toHtml() In [6 ]: result Out[6 ]: PyQt4.QtCore.QString(u'<!DOCTYPE html><html><head>\n <title>111</title>\n</head>\n<body>\n<script type="text/javascript">\n document.body.appendChild(document.createTextNode(String.fromCharCode(84,48,48,76,83)));\n</script>T00LS\n\n</body></html>' )
可以发现和requests不同,Html内JavaScript已经执行并在html里面插入了T00LS这样的节点。这样我们就可以获取并匹配Js执行之后的内容T00LS,保证Xss测试用的Payload在浏览器是可以被执行的,减少误报。
修改后的xss检测插件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 import sys from PyQt4.QtGui import * from PyQt4.QtCore import * from PyQt4.QtWebKit import * from lxml import html class Render (QWebPage) : def __init__ (self, url) : self.app = QApplication(sys.argv) QWebPage.__init__(self) self.loadFinished.connect(self._loadFinished) self.mainFrame().load(QUrl(url)) self.app.exec_() def _loadFinished (self, result) : self.frame = self.mainFrame() self.app.quit() def xss_detect (method='GET' , querylist=[], url='' ) : params = {} resp = None payload = '-->\'"><script>document.body.appendChild(document.createTextNode(String.fromCharCode(84,48,48,76,83)));</script>' if method == 'GET' : for query in querylist: url = '{url}?{query}={payload}' .format(url=url,query=query,payload=payload) r = Render(url) result = r.frame.toHtml() resp = str(result.toAscii()) print resp if resp: if 'T00LS' in resp: return True else : return False print xss_detect(querylist=['id' ,], url='https://192.168.1.126/xss.php' )
分别对上面构造的两个php脚本进行检测,可以发现不会出现相同的误报了。
这种方法保证了我们所插入的Js代码确实在浏览器能执行,实际的环境中,我们应该让Js生成比T00LS更加复杂得多的字符,这样就可以避免误报了。
本博客所有内容只用于安全研究,请勿用于恶意攻击。